
Decentralized data storage is a distributed computing paradigm that allows users to store and retrieve data in a decentralized manner, without the need for a central authority or coordinator. This approach has the potential to offer a number of benefits compared to traditional, centralized storage systems, such as improved reliability, security, and scalability.
In order to provide these benefits, decentralized storage systems rely on a variety of techniques and algorithms to store, manage, and retrieve data. In this article, we will provide an overview of these techniques and algorithms, including replication, erasure coding, distributed hash tables, and consensus protocols. We will also discuss the trade-offs and considerations involved in choosing the right approach for decentralized storage.
After publishing an article in august 2022 on How Decentralized Storage is Transforming Data Management, I decided a more technical article was also necessary.
By understanding the technicalities of decentralized storage, we can gain a deeper appreciation for the design and operation of these systems, and how they can be used to solve real-world problems.
Contents
Data distribution algorithms
Fault tolerance algorithms
Distributed database algorithms
Distributed file system algorithms
Synchronization algorithms
Coordination algorithms
Resource management algorithms
Communication protocols
Network routing algorithms
Distributed systems
Distributed systems are computer systems that consist of multiple interconnected nodes that work together to perform a common task. These nodes can be located in the same physical location or dispersed across different locations, and communicate with each other over a network.
Distributed systems offer several benefits over traditional centralized systems, including increased reliability, scalability, and performance. They can also be more flexible and adaptable, as the nodes in the system can be added or removed as needed.
However, distributed systems also introduce new challenges and complexities, such as the need to coordinate the actions of the nodes, manage data consistency and integrity, and ensure fault tolerance. To address these challenges, distributed systems rely on a variety of algorithms and protocols, such as consensus algorithms, resource management algorithms, and distributed data structures.
Replication is a technique used to increase the availability and durability of data in a distributed system. In a replication system, multiple copies of data are stored on different nodes in the system, so that if one copy becomes unavailable or lost, the data can still be accessed from one of the other copies.
There are several different algorithms that can be used to implement replication in a distributed system. These algorithms can differ in terms of the level of consistency they provide, the performance and overhead they incur, and the fault tolerance they offer.
Some common types of replication algorithms include:
-
Full replication: In this approach, every node in the system stores a complete copy of the data. This provides high availability and fault tolerance, but can be inefficient in terms of storage and bandwidth usage.
-
Partial replication: In this approach, only a subset of the nodes in the system store copies of the data. This can be more efficient than full replication, but may offer lower availability and fault tolerance.
-
Quorum-based replication: In this approach, a minimum number of copies of the data must be available in order for it to be considered “live.” This can provide a good balance between availability and efficiency, but may be more complex to implement.

Erasure coding is a technique for storing data in a redundant manner, such that the original data can be reconstructed from a subset of the stored data. This is done by adding redundant information to the data, in the form of extra “parity” data. If some of the stored data is lost or becomes unavailable, the original data can be reconstructed using the remaining data and the parity data.
Erasure coding allows for more efficient storage compared to simple replication, as it requires the storage of less data overall. For example, if data is replicated three times, three copies of the data must be stored, which can be inefficient in terms of storage space. On the other hand, if data is encoded using an erasure code with a 2:1 ratio, only two copies of the data and one copy of the parity data need to be stored, which is more space-efficient.
Erasure coding is often used in decentralized storage systems to ensure the durability and availability of data. It can be implemented using various mathematical techniques, such as finite field arithmetic or polynomial interpolation.
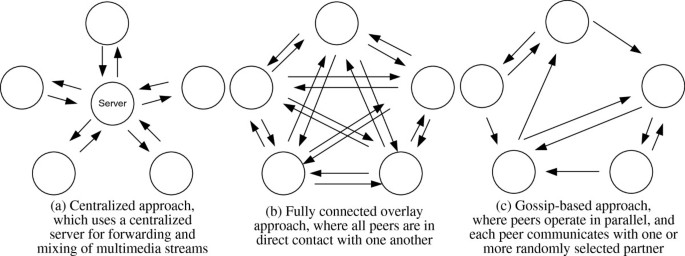
Gossip protocols are distributed protocols that allow nodes in a decentralized system to communicate and exchange information with each other, without the need for a central coordinator. In a gossip protocol, nodes periodically exchange small pieces of information, or “gossip,” with their neighbors in the network. Over time, this gossip spreads throughout the network and eventually reaches all nodes, allowing them to stay informed about the state of the system.
Gossip protocols can be used for a variety of tasks in decentralized systems, such as disseminating information about the state of the system, detecting and repairing errors, and maintaining consistency. They are often used in distributed systems that require high availability and fault tolerance, as they are relatively simple to implement and can operate effectively in the presence of failures or network disruptions.
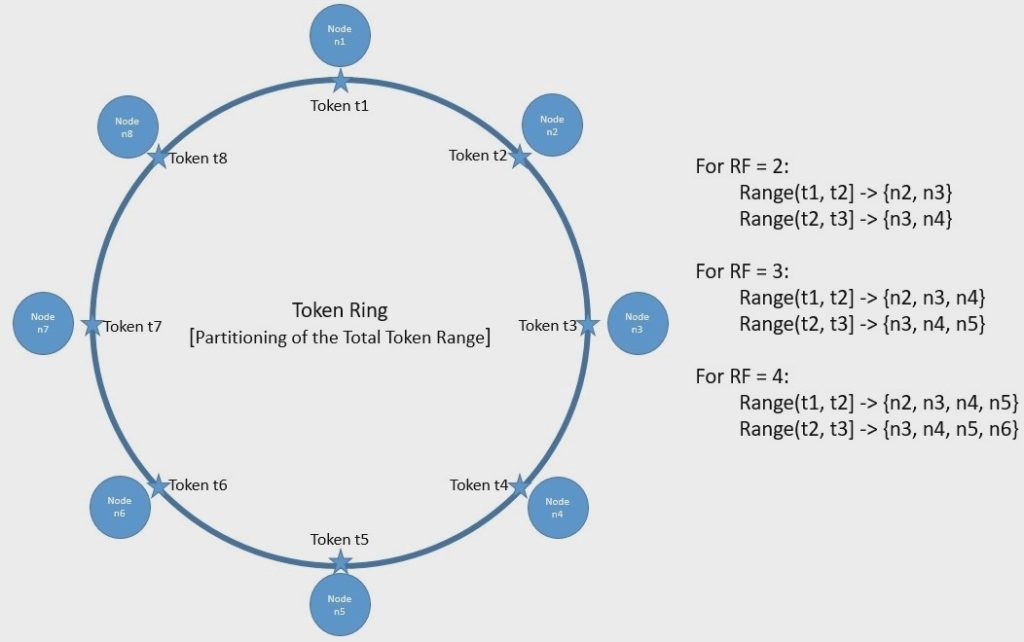
Distributed hash tables (DHTs)
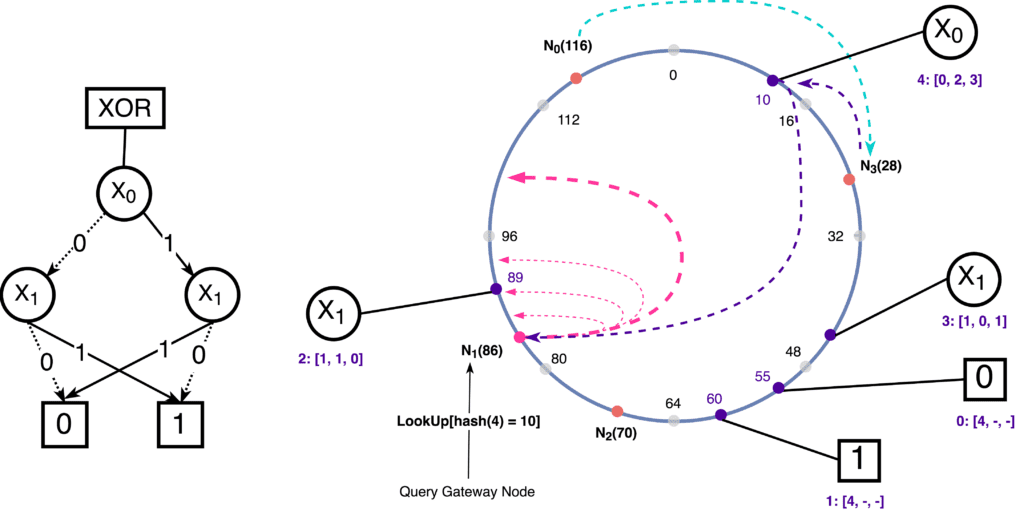
Distributed hash tables (DHTs) are a type of distributed data structure that allows nodes in a decentralized system to store and retrieve data using a key-value store. DHTs use a hash function to map keys to nodes in the system, and data is stored on the nodes responsible for the corresponding keys.
DHTs have several key features that make them useful for decentralized storage systems:
-
Efficiency: DHTs can provide efficient data retrieval, as keys can be quickly mapped to the nodes responsible for storing the corresponding data.
-
Scalability: DHTs can scale well as the number of nodes in the system increases, as the keyspace can be partitioned among the nodes in a balanced manner.
-
Resilience: DHTs can be resistant to failures, as data can still be accessed if some nodes become unavailable. However, they may have lower fault tolerance compared to replication-based approaches.
-
Simplicity: DHTs are relatively simple to implement and use, making them a popular choice for decentralized storage systems.
DHTs are used in a variety of decentralized systems, including distributed file systems, peer-to-peer networks, and decentralized storage systems.
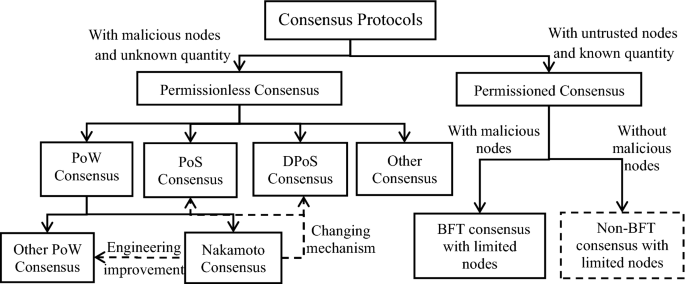
Consensus protocols are algorithms that allow nodes in a decentralized system to reach agreement on a single value or decision. These algorithms are used to ensure the consistency and integrity of data in a distributed system, even in the presence of failures or network disruptions.
There are several different types of consensus protocols, including:
Consensus protocols play a critical role in decentralized storage systems, as they ensure the consistency and integrity of the data stored in the system. They also help to ensure the reliability and fault tolerance of the system, as they allow the system to recover from errors and continue to operate correctly in the presence of failures or network disruptions.
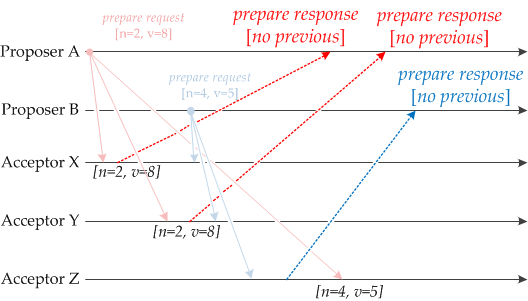
The Paxos algorithms are a family of consensus protocols developed by computer scientist Leslie Lamport. They allow nodes in a distributed system to reach agreement on a single value, even in the presence of failures or network disruptions.
There are several different variations of Paxos, including the Basic Paxos algorithm and the Multi-Paxos algorithm. The basic idea behind Paxos is to use a series of messages and voting to reach agreement among the nodes in the system.
In the Basic Paxos algorithm, nodes in the system take turns proposing values and voting on them. If a majority of nodes vote for a particular value, it is considered the agreed-upon value. If a node fails or becomes unavailable, the algorithm can still reach agreement by allowing other nodes to take its place.
The Multi-Paxos algorithm is a variant of the Basic Paxos algorithm that allows multiple values to be proposed and agreed upon in parallel. This can improve the performance and scalability of the system, as it allows multiple decisions to be made simultaneously.
Paxos algorithms are widely used in distributed systems that require high availability and fault tolerance, such as distributed databases, file systems, and messaging systems. They are known for their reliability and efficiency, although they can be somewhat complex to understand and implement.
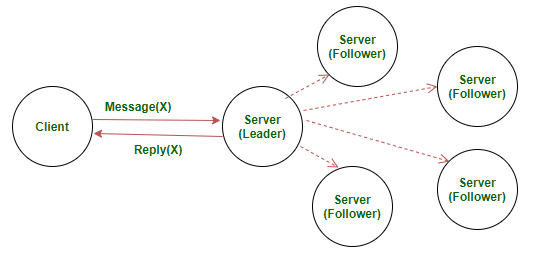
The Raft algorithm is a consensus protocol that was developed as an alternative to the Paxos algorithms. It is designed to be easier to understand and implement than Paxos, and is often used in distributed systems that require high availability and fault tolerance.
Like Paxos, the Raft algorithm allows nodes in a distributed system to reach agreement on a single value, even in the presence of failures or network disruptions. It does this by using a series of messages and voting to reach consensus among the nodes in the system.
One key difference between Raft and Paxos is that Raft divides the nodes in the system into distinct roles, including leaders and followers. The leader node is responsible for proposing values and collecting votes, while the follower nodes vote on the proposed values and apply them to their local state. This division of roles can make Raft easier to understand and implement compared to Paxos.
Raft is also designed to be more fault-tolerant than Paxos, as it allows nodes to recover from failures more quickly and automatically. This can make it a good choice for distributed systems that require high availability and reliability.
Byzantine fault tolerance (BFT) protocols
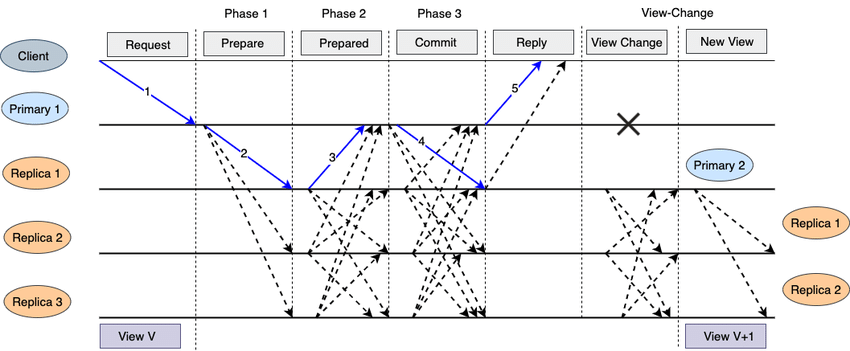
Byzantine fault tolerance (BFT) protocols are a class of consensus protocols that are designed to tolerate malicious behavior by some of the nodes in the system. These protocols are named after the “Byzantine generals problem,” which refers to the challenge of achieving consensus among a group of nodes that may be unreliable or untrusted.
BFT protocols use complex cryptographic techniques to ensure the integrity of the system, even in the presence of malicious nodes. They are often used in mission-critical systems that require high security and reliability, such as military systems and financial systems.
There are several different types of BFT protocols, including practical BFT (PBFT) and proof-of-stake (PoS) protocols. PBFT protocols use a combination of messages and voting to reach consensus, and can tolerate up to a third of the nodes in the system behaving maliciously. PoS protocols use cryptographic signatures and economic incentives to ensure the integrity of the system, and can tolerate a larger fraction of malicious nodes.
BFT protocols are more complex and resource-intensive than other types of consensus protocols, such as the Paxos algorithms and the Raft algorithm. However, they offer a high level of security and reliability, making them a good choice for systems that require strong guarantees against Byzantine failures.
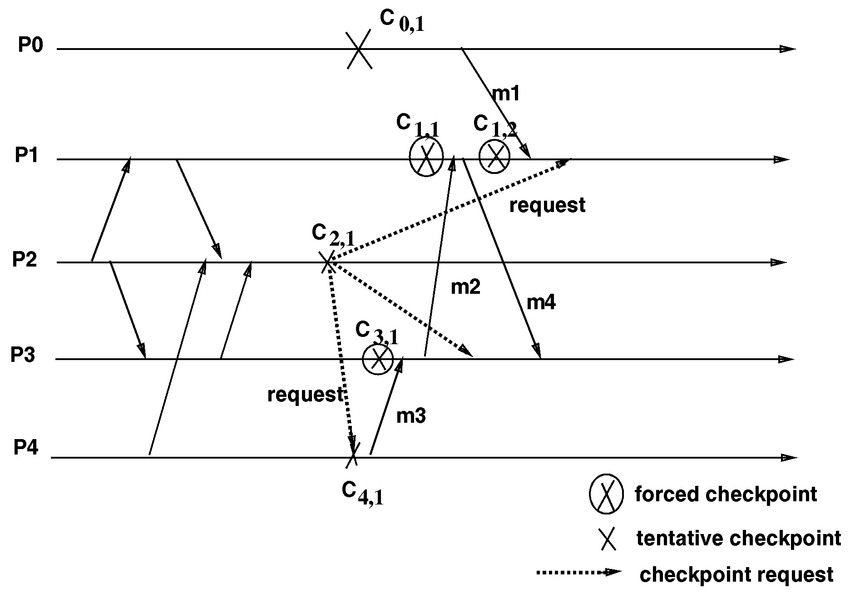
A checkpointing algorithm is a type of fault tolerance algorithm that is used to recover from failures in a distributed system. It works by periodically saving the state of the system to a stable storage location, so that the system can be restored to a known good state in the event of a failure.
The basic idea behind checkpointing is that if a node in the system fails, the system can recover by rolling back to the last known good state and replaying any updates that occurred after that state. This can help to minimize downtime and data loss in the event of a failure.
There are several different types of checkpointing algorithms, including periodic checkpointing, incremental checkpointing, and coordinated checkpointing. Each of these approaches has its own trade-offs in terms of overhead, recovery time, and data loss.
Checkpointing algorithms are often used in distributed systems that require high availability and fault tolerance, such as distributed databases and distributed file systems. They can be an effective way to ensure the reliability and consistency of the system, although they may have some overhead and complexity.
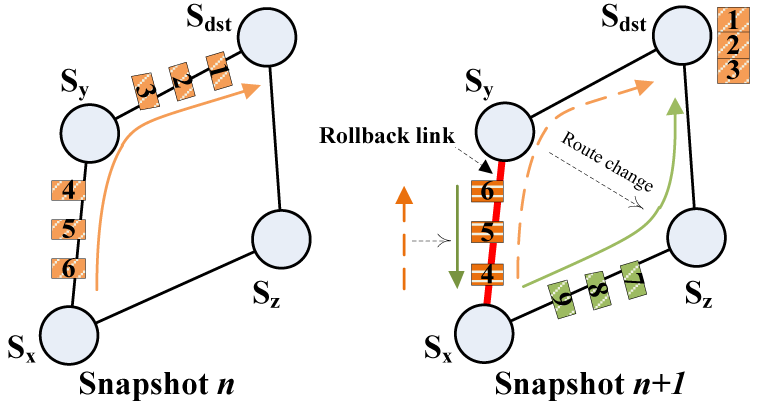
Rollback algorithms are a type of fault tolerance algorithm that is used to recover from failures in a distributed system. They work by rolling back the system to a known good state in the event of a failure, and then replaying any updates that occurred after that state to bring the system up to date.
Rollback algorithms are similar to checkpointing algorithms, in that they both involve saving the state of the system to a stable storage location and using that state to recover from failures. However, rollback algorithms typically involve rolling back the entire system to a previous state, rather than just a single node or component.
There are several different types of rollback algorithms, including snapshot rollback, version rollback, and transaction rollback. Each of these approaches has its own trade-offs in terms of overhead, recovery time, and data loss.
Rollback algorithms are often used in distributed systems that require high availability and fault tolerance, such as distributed databases and distributed file systems. They can be an effective way to ensure the reliability and consistency of the system, although they may have some overhead and complexity.
Distributed indexing algorithms
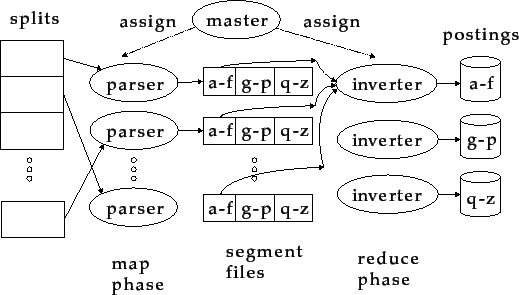
Distributed indexing algorithms are used to store and retrieve data in a distributed database system. They work by creating an index structure that maps keys to the locations of the corresponding data records in the database.
There are several different types of distributed indexing algorithms, including hash-based indexing, range-based indexing, and tree-based indexing. Each of these approaches has its own trade-offs in terms of performance, scalability, and fault tolerance.
Hash-based indexing algorithms use a hash function to map keys to nodes in the system, and data is stored on the nodes responsible for the corresponding keys. This can provide good performance and scalability, but may have lower fault tolerance compared to other approaches.
Range-based indexing algorithms divide the keys into ranges and assign each range to a specific node in the system. This can provide good performance and scalability, but may require more complex management of the key ranges as the system grows or changes.
Tree-based indexing algorithms use a tree structure to store the index information, and can support efficient queries and updates. However, they may have lower scalability and higher overhead compared to other approaches.
Distributed query processing algorithms
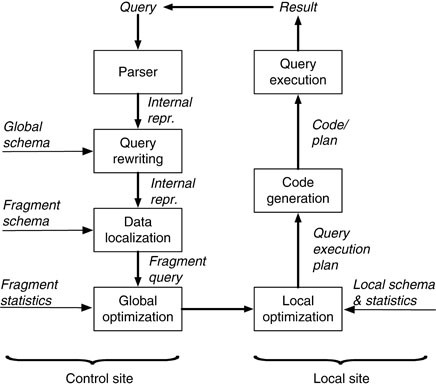
Distributed query processing algorithms are used to execute queries on a distributed database system. They work by dividing the query into subqueries that can be processed by different nodes in the system, and then combining the results of the subqueries to produce the final result.
There are several different approaches to distributed query processing, including divide-and-conquer algorithms, pipelining algorithms, and broadcast algorithms. Each of these approaches has its own trade-offs in terms of performance, scalability, and fault tolerance.
Divide-and-conquer algorithms divide the query into smaller subqueries that can be processed independently, and then combine the results to produce the final result. This can provide good performance and scalability, but may require more complex management of the subqueries.
Pipelining algorithms divide the query into stages, and pass the intermediate results from one stage to the next as the query is processed. This can provide good performance and scalability, but may have higher overhead compared to other approaches.
Broadcast algorithms send the entire query to all nodes in the system, and have each node return the relevant part of the result. This can be simple to implement, but may have lower performance and scalability compared to other approaches.
Distributed transaction processing algorithms
![]()
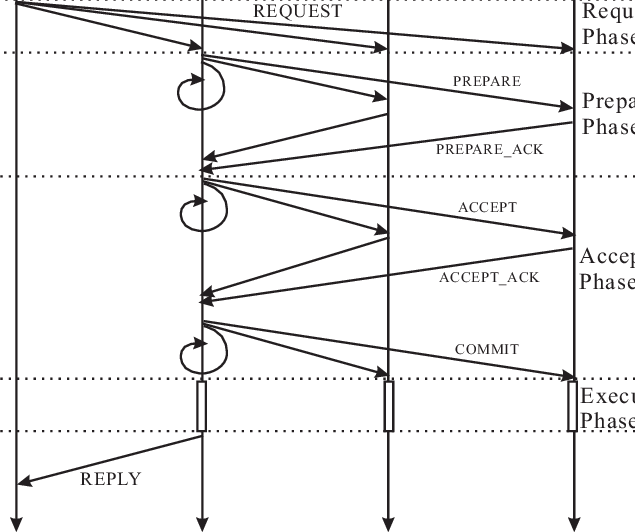
Distributed transaction processing algorithms are used to ensure the consistency and integrity of data in a distributed database system. They work by coordinating the updates to the database made by multiple transactions, in order to ensure that the updates are atomic, consistent, isolated, and durable (ACID).
There are several different approaches to distributed transaction processing, including two-phase commit (2PC) and three-phase commit (3PC) algorithms.
Two-phase commit algorithms are used to coordinate the updates made by a single transaction across multiple nodes in the system. They involve a two-phase protocol in which the nodes first prepare to commit the updates, and then either commit or roll back the updates based on the outcome of the transaction. 2PC algorithms can provide good performance and scalability, but may have lower fault tolerance compared to other approaches.
Three-phase commit algorithms are similar to 2PC algorithms, but involve an additional “pre-commit” phase in which the nodes prepare to commit the updates. This can provide higher fault tolerance and better recovery from failures, but may have higher overhead and complexity compared to 2PC algorithms.

File allocation algorithms are used to determine how files should be distributed among the nodes in a distributed file system. These algorithms can take into account factors such as available storage space, network connectivity, and workload to make efficient allocation decisions.
There are several different types of file allocation algorithms, including:
File distribution algorithms and striping
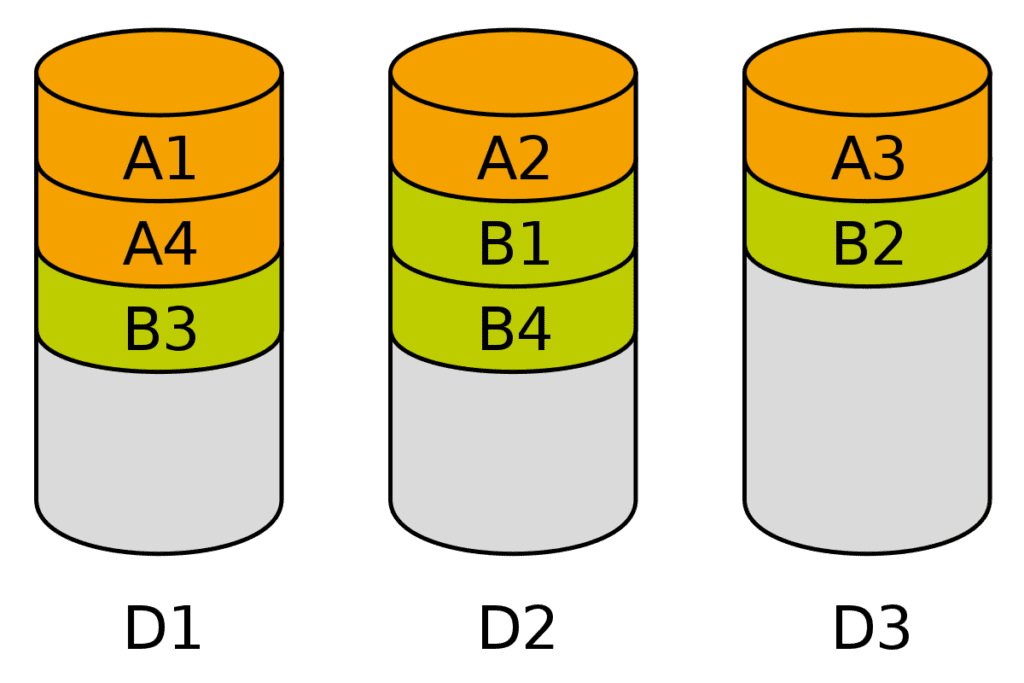
File distribution algorithms are used to determine how data should be divided into blocks and distributed among the nodes in a distributed file system. These algorithms can take into account factors such as data locality and network topology to optimize data access and transfer performance.
One type of file distribution algorithms we haven’t already mentions aside from Replication and Erasure coding is striping.
In striping, data is divided into blocks and distributed across the nodes in the system in a round-robin manner. This can provide good performance and scalability, but may have lower fault tolerance compared to other approaches.
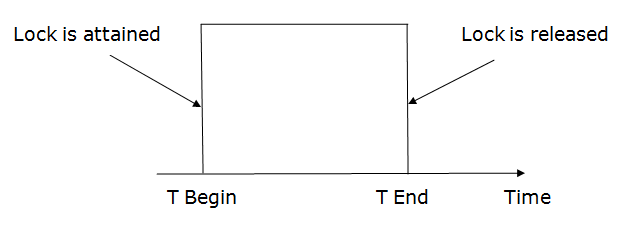
Lock-based algorithms are a type of synchronization algorithm that is used to coordinate the actions of multiple threads or processes in a distributed system. They work by allowing only one thread or process to acquire a lock on a shared resource at a time, and requiring other threads or processes to wait until the lock is released before they can access the resource.
There are several different types of lock-based algorithms, including:
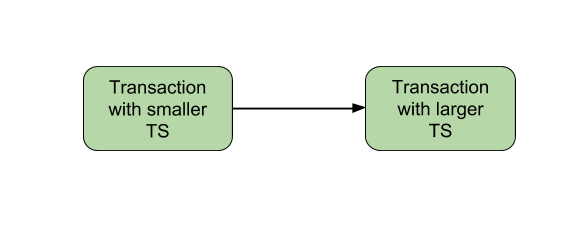
Timestamp-based algorithms are a type of synchronization algorithm that is used to coordinate the actions of multiple threads or processes in a distributed system. They work by assigning a unique timestamp to each thread or process, and using the timestamps to order the access to shared resources.
There are several different types of timestamp-based algorithms, including:
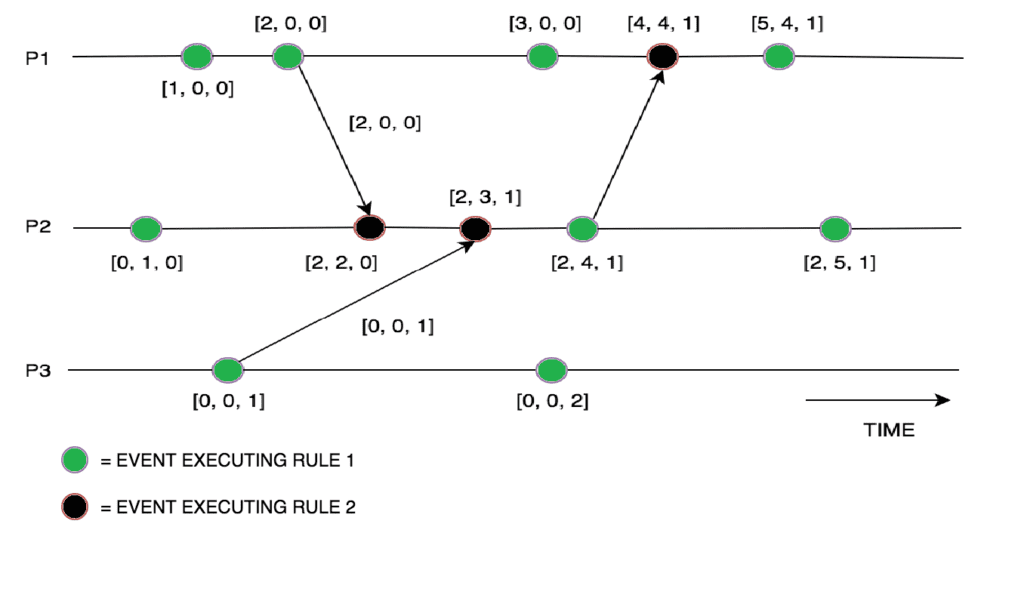
Vector clocks are a type of logical clock that is used to track the causal dependencies between events in a distributed system. Each node in the system maintains a local clock, and assigns a unique timestamp to each event based on the current value of the clock. The timestamps are stored in a vector, and can be used to determine the order in which events occurred and the causal relationships between them.
Vector clocks are often used in distributed systems that need to ensure consistency and detect conflicts between updates made by different nodes. For example, a distributed database may use vector clocks to track the order in which updates are made to different records, and to resolve conflicts when multiple updates are made concurrently.
Vector clocks are similar to Lamport timestamps, which are another type of logical clock used in distributed systems. However, vector clocks can track more complex causal relationships between events, and can be used to determine whether two events are concurrent or causally related.
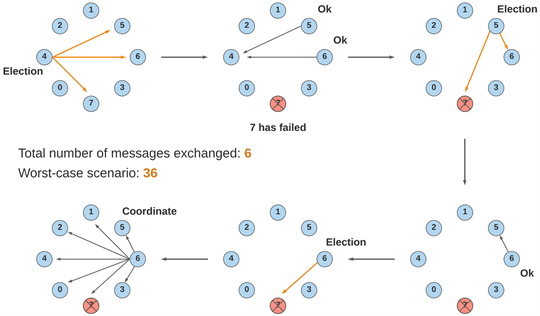
Leader election algorithms are used to select a leader or coordinator from among a group of nodes in a distributed system. The leader is responsible for coordinating the actions of the other nodes, and may be responsible for tasks such as resource allocation, task scheduling, or data management.
There are several different approaches to leader election, including:
Clock synchronization algorithm
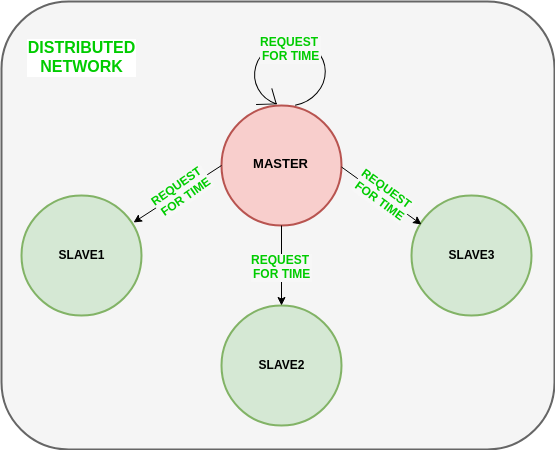
Clock synchronization algorithms are used to ensure that the clocks on different nodes in a distributed system are kept in sync with each other. This is important for many applications, as the correct order of events and the duration of events may depend on the accuracy of the clocks.
There are several different approaches to clock synchronization, including:
Distributed mutual exclusion algorithms
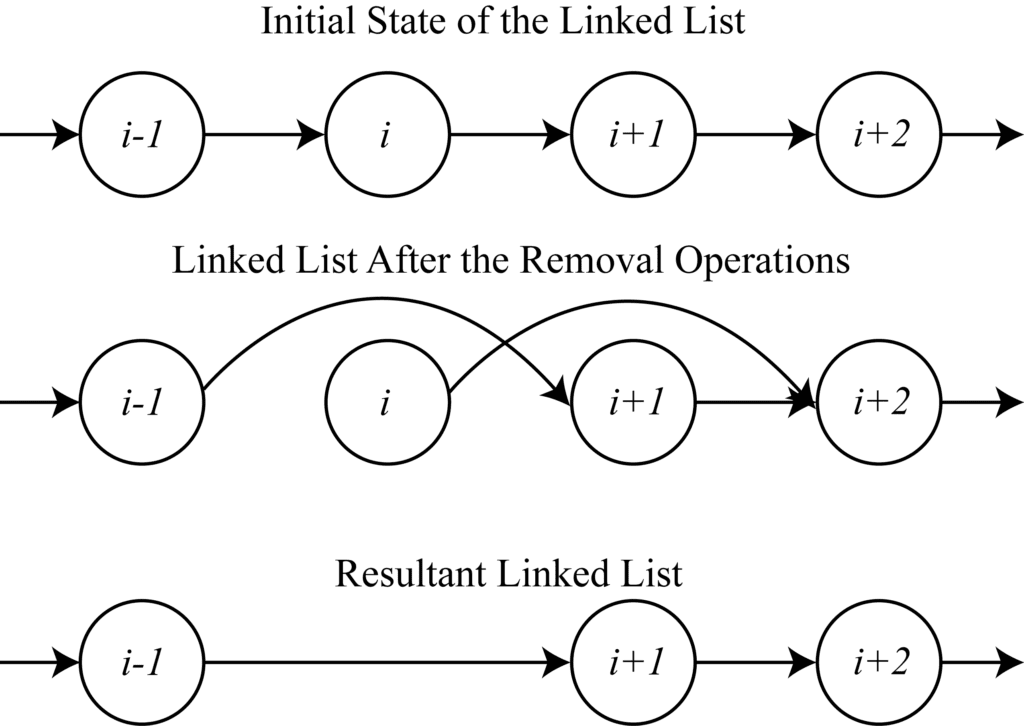
Distributed mutual exclusion algorithms are used to coordinate the access to shared resources in a distributed system. They work by allowing only one node in the system to acquire a lock on the shared resource at a time, and requiring other nodes to wait until the lock is released before they can access the resource.
There are several different approaches to distributed mutual exclusion, including:
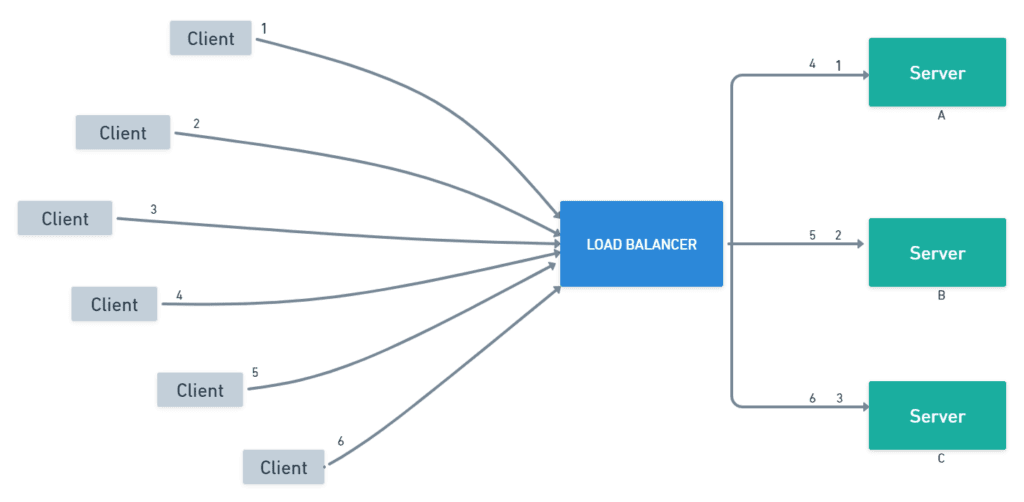
Load balancing algorithms are used to distribute workload evenly among the nodes in a distributed system, in order to improve system performance and scalability. These algorithms can take into account factors such as the current workload and capacity of each node, as well as network latency and other performance metrics, to make efficient allocation decisions.
There are several different types of load balancing algorithms, including:
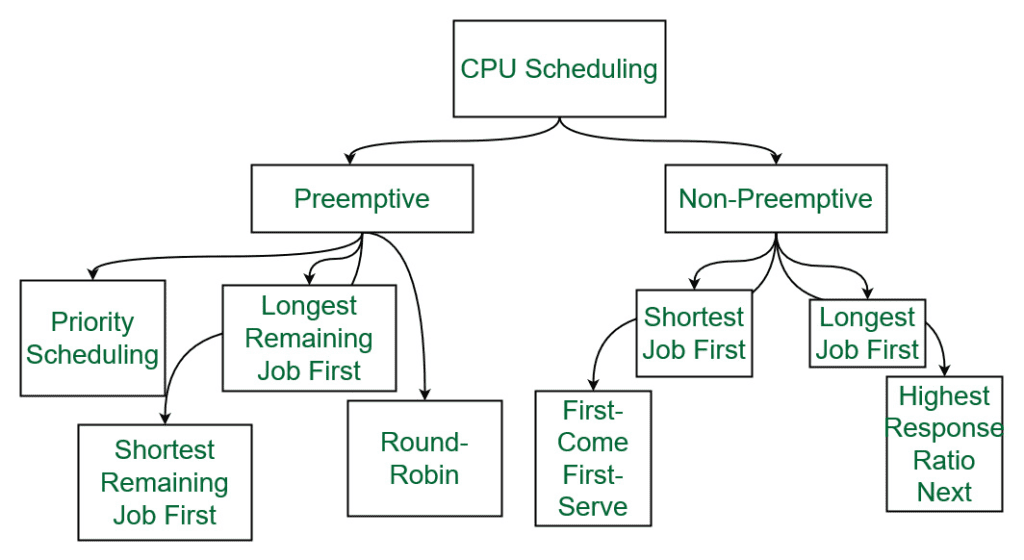
Scheduling algorithms are used to determine the order in which tasks should be executed in a distributed system. These algorithms can take into account factors such as task dependencies, resource availability, and performance goals to make efficient scheduling decisions.
There are several different types of scheduling algorithms, including:
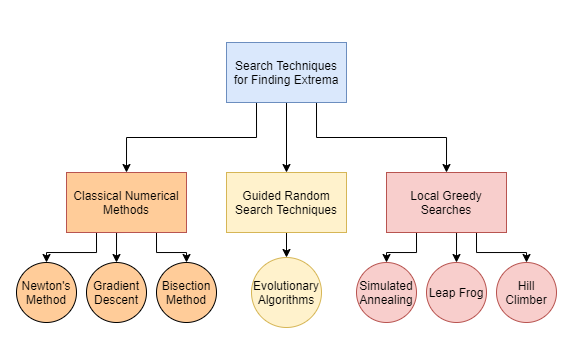
Optimization algorithms are a class of algorithms that are used to find the optimal solution to a problem, given certain constraints. These algorithms are widely used in a variety of fields, including engineering, finance, and machine learning, to solve problems such as resource allocation, portfolio optimization, and model selection.
There are several different types of optimization algorithms, including:
Message passing protocols are communication protocols that are used to facilitate the exchange of messages or data between two or more devices over a network. In a message passing protocol, devices can send messages or data to each other directly, rather than going through a central server as in a publish-subscribe protocol.
There are many different types of message passing protocols, including:
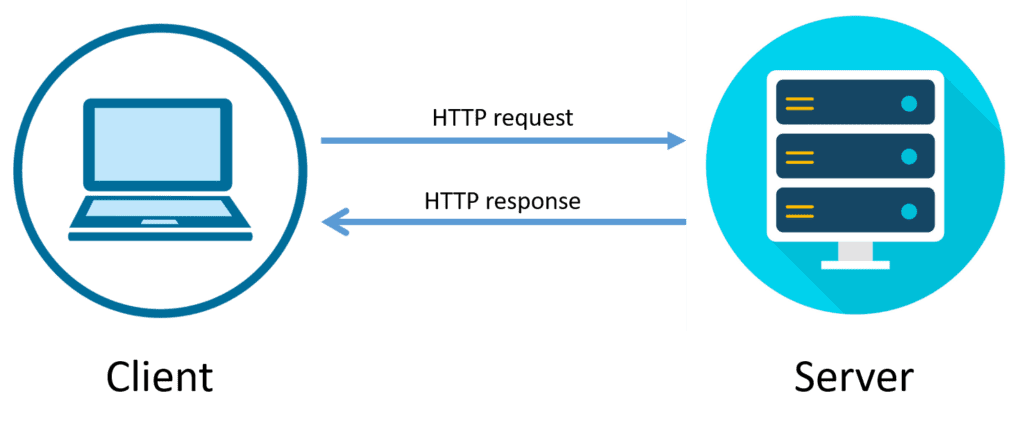
Request-response protocols are communication protocols that are used to facilitate the exchange of information between two or more devices over a network. In a request-response protocol, one device (the client) sends a request for information to another device (the server), and the server responds with the requested information.
There are many different types of request-response protocols, including:
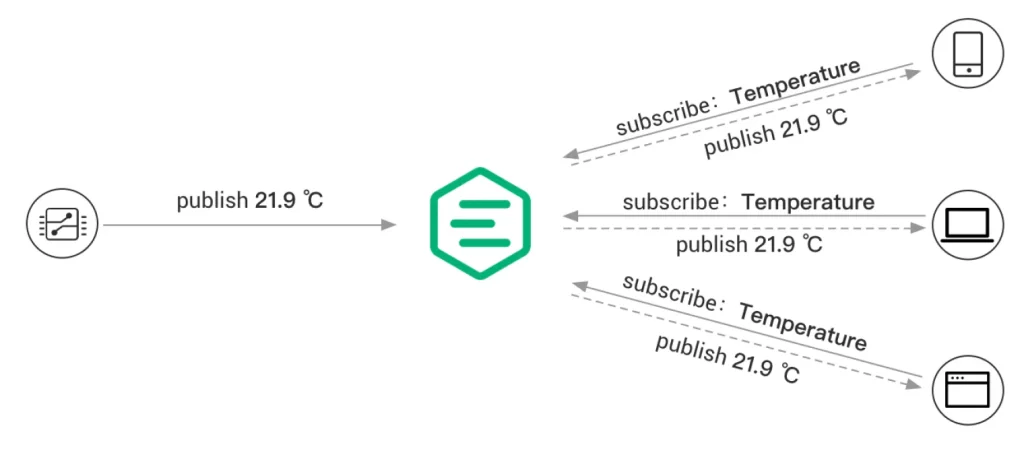
Publish-subscribe protocols are communication protocols that are used to facilitate the exchange of information between two or more devices over a network. In a publish-subscribe protocol, one or more devices (publishers) send messages or data to a central server (the broker), and other devices (subscribers) receive the messages or data by subscribing to the broker.
There are many different types of publish-subscribe protocols, including:
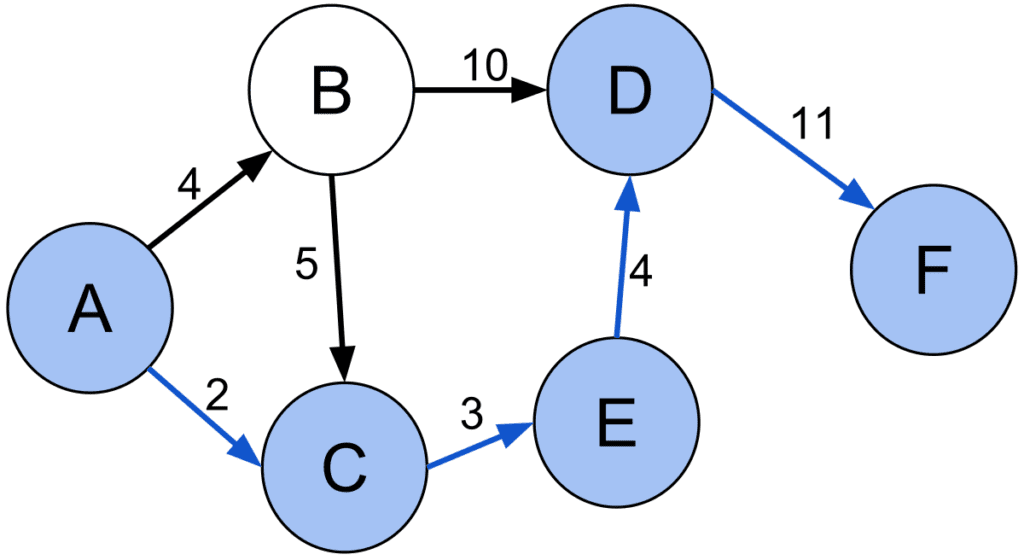
Shortest path algorithms are a class of algorithms that are used to find the shortest path between two nodes in a graph. These algorithms are widely used in a variety of fields, including computer science, transportation planning, and geographic information systems, to solve problems such as routing, navigation, and network design.
There are several different types of shortest path algorithms, including:
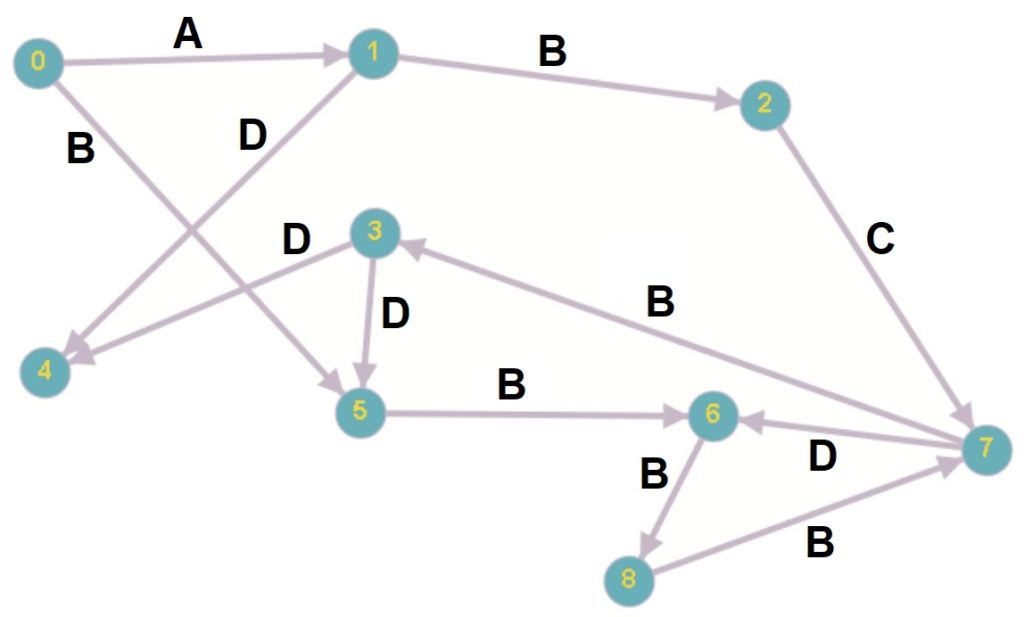
Minimum hop algorithms are a class of algorithms that are used to find the shortest path between two nodes in a graph in terms of the number of hops (edges) that must be traversed. These algorithms are commonly used in networking applications to find the route with the fewest number of intermediate routers or switches between two nodes on a network.
There are several different types of minimum hop algorithms, including:
Load-balanced routing algorithms
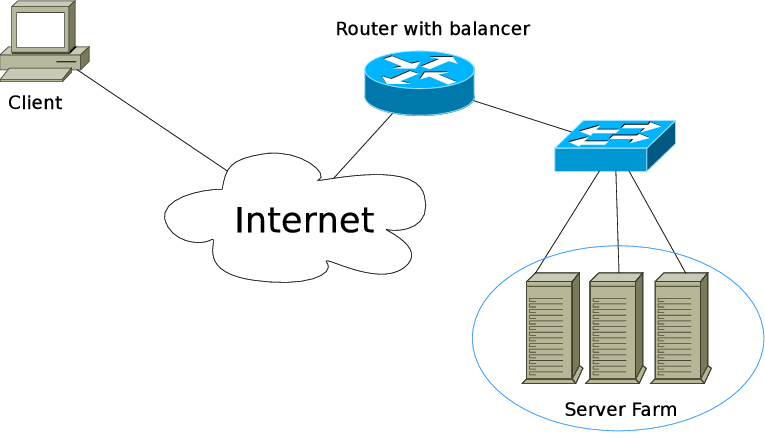
Load-balanced routing algorithms are a class of algorithms that are used to distribute traffic across multiple routes or servers in order to balance the load and improve performance. These algorithms are commonly used in networking and distributed systems to optimize the use of resources and prevent bottlenecks.
There are several different types of load-balanced routing algorithms, including:
In conclusion, algorithms play a crucial role in distributed systems, helping to solve a wide range of problems involving data distribution, resource management, and communication. There are many different types of algorithms used in distributed systems, including data distribution algorithms, resource management algorithms, and distributed file system algorithms, as well as more specialized algorithms such as consistent hashing, replication algorithms, erasure coding, and gossip protocols. These algorithms are an essential part of the infrastructure of distributed systems, and help to ensure that these systems are efficient, scalable, and reliable.